Essofore - a document store powered by semantic search
What is Essofore?
Essofore is a document store powered by a semantic search engine that understands the meaning of your query rather than searching for keywords in your query. It is the only RAG infrastructure that runs entirely in your AWS account — your data never leaves your VPC, costs stay flat no matter how much data you index, and you don't need to understand embeddings to use it.
Who is it for?
You are a developer in a large organization in charge of developing their enterprise search or RAG applications.
Top 3 Problems Solved
- Developer Productivity: Enterprise grade without the over-engineering associated with enterprise software. Zero embedding knowledge required. Upload your PDFs and Word docs. Search in plain English. Essofore handles chunking, embedding generation, vector storage, and retrieval automatically — no ML expertise needed.
- Costs: Flat and transparent pricing per month independent of usage or data volume.
- Security: Your data never leaves your AWS VPC. No SaaS vendor has access to your documents — ever. Critical for healthcare, fintech, legaltech, and any team with a CISO. Do you trust third parties will not mine your data? How safe do you think your data is with them? Have you read their data leak and compromise reports [1, 2, 3]? What compensation are they providing you if your data is hacked? The best way to protect your data is not to give it away.
Top 10 Highlights
- Document database powered by AI search that relieves developers from having to work with multiple fragmented services.
- No data is ever sent to OpenAI or any other 3rd party. 100% secure, confidential, on-prem and non-SaaS.
- Use it as the retriever in your RAG pipeline or to power your enterprise search.
- Simple to use, reliable and developer friendly API backed by an OpenAPI specification
- No complex setup. Ready-to-use out of the box with no explicit configuration. No need to install a dozen dependencies just to get started.
- Index approx. 100MB of text per GB of RAM (entire works of Shakespeare < 6MB of text)
- Ingest 3-23 GB of data / day (single node). 4GB = 1B tokens. 3GB w/ AMD EPYC-Rome Processor w/ 14 vCPU. 23 GB using NVIDIA RTX A6000 GPU.
- Leverage multiple CPUs with linear scaling of throughput (vs. # of threads) and index size (vs. amount of data)
- State-of-the-art support for deletion requiring no vacuum process (a.k.a. lazy deletions)
- Support for text, pdf, html and MS Office (doc, xls, ppt) formats
Performance
| Throughput vs. threads | Index Size vs. # of vectors |
|---|---|
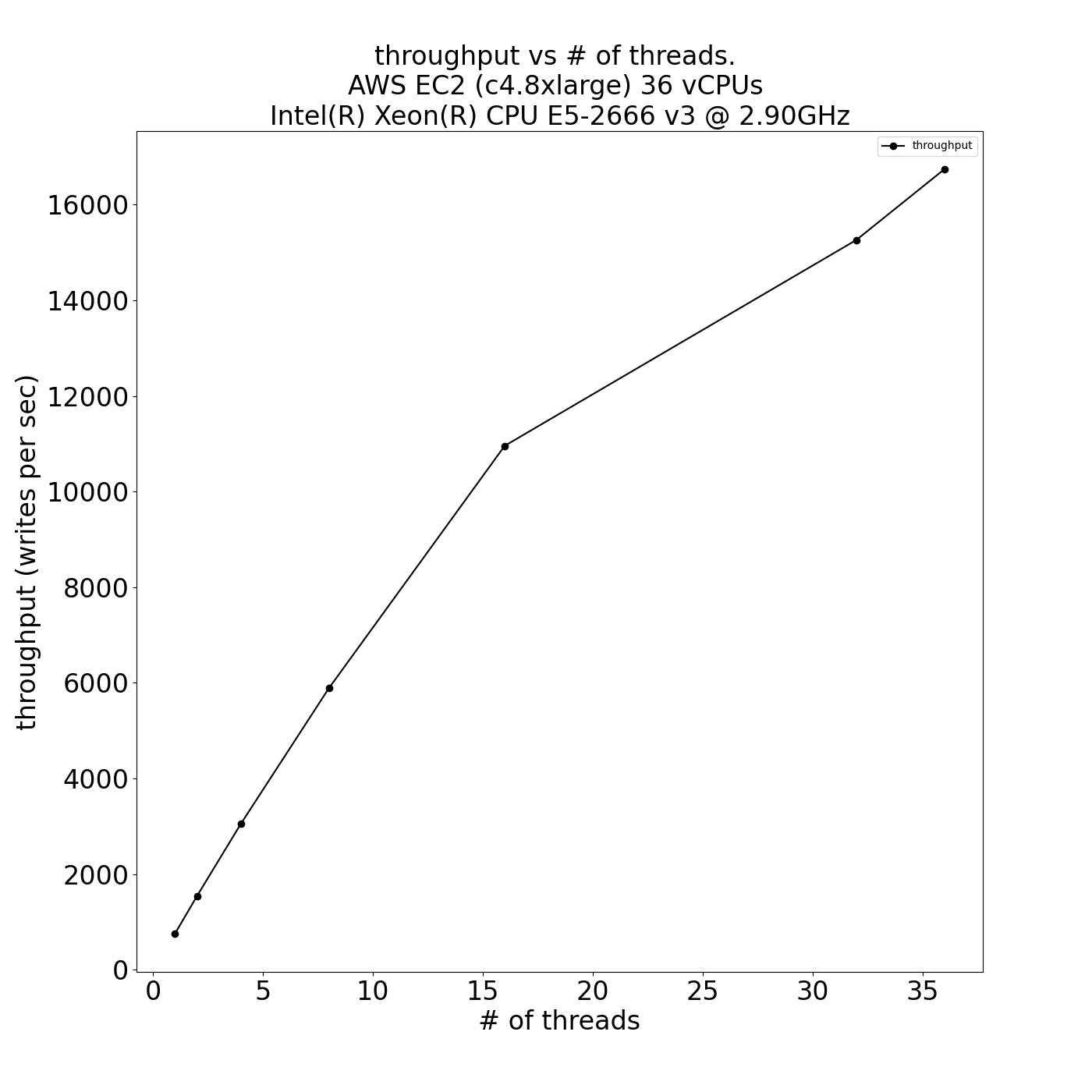 | 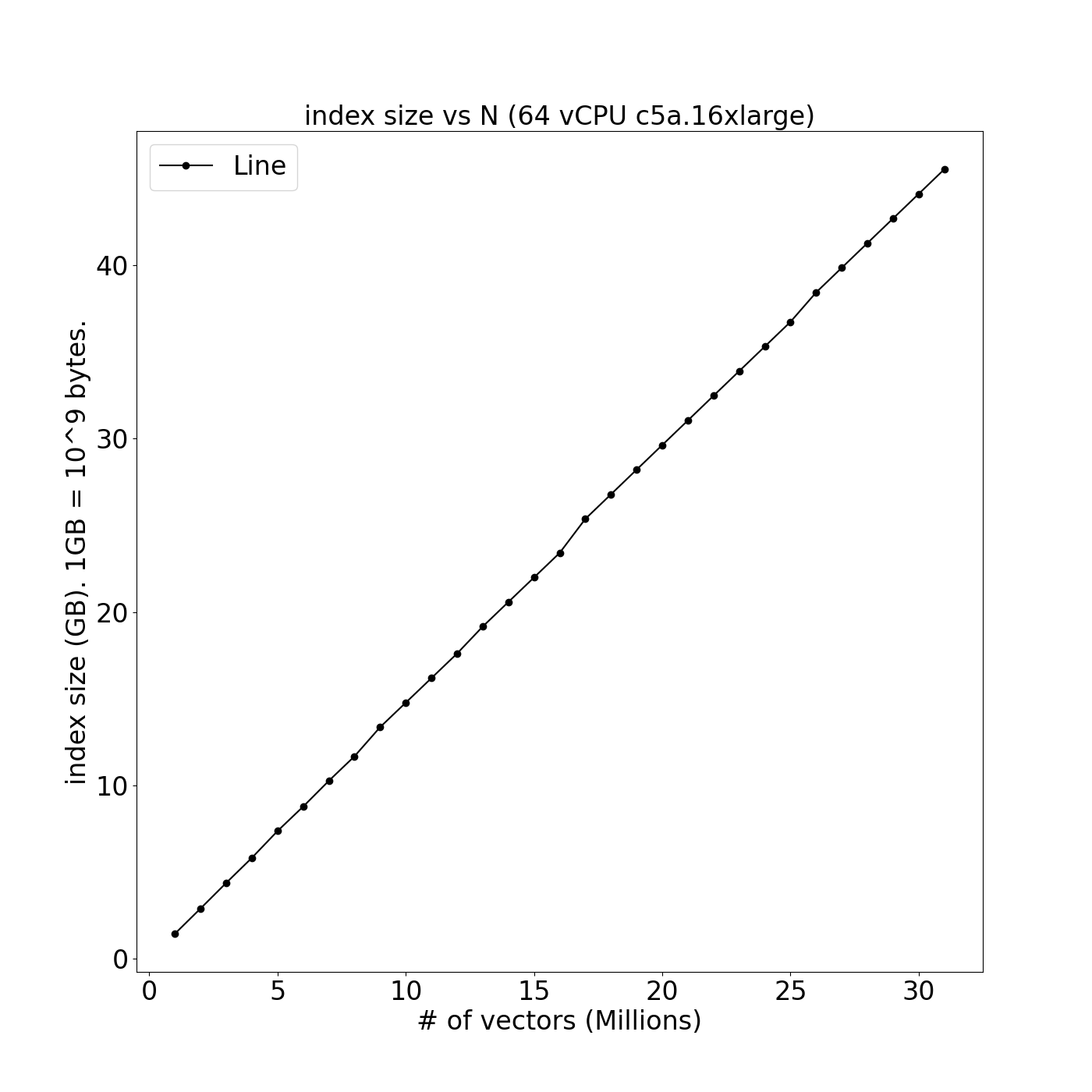 |
Example
from essofore_client.api.collections import create_collection, upload_document, search
from essofore_client.models.document_type import DocumentType
create_collection.sync_detailed(collection_id="1", title="Sherlock Holmes", client=client)
with open(file, 'rb') as f:
upload_document.sync_detailed(client=client,
collection_id = "1",
document_id = "pg2350",
title="The Hound of the Baskervilles",
doc_type=DocumentType.TXT,
source_url = url,
body=Blob(f))
response = search.sync_detailed(client=client, collection_id="1", q="Who is Sherlock Holmes?", k=5)
for r in response.parsed:
print_search_result(r)
Get Started on AWS or Contact Us for more options.
Also check out Supply Chain Route Optimization and our LinkedIn page for more products and services.